


Occasionally you’ll find yourself wanting to query data from a database. I know I do! Sometimes that involves grouping your data.
Sometimes you want to group your groups and pull specific data from those groups.
Lots of grouping! Today we’ll look at how we’d tackle this in SQL Server, without having to resort to manually querying for and iterating over whole collections just to get at what we want.
The Problem to Solve
Let’s say we want to query for Orders placed in our system, to see what the highest-rated Item is for each Order. This means that we will have to group our sets of Order Items together by Order, and then from there collect a subset of Item data from each Order.
Database Setup
A Simple Schema
First, let’s establish our database schema that we’ll use to demonstrate the tools we have available to solve our problem.
CREATE TABLE Orders (
ID INT IDENTITY(1, 1),
Date DATETIMEOFFSET NOT NULL DEFAULT GETDATE(),
PRIMARY KEY(ID)
);
CREATE TABLE Items (
ID INT IDENTITY(1, 1),
Name VARCHAR(100),
Price DECIMAL(18, 2) NOT NULL,
Rating INT NOT NULL,
PRIMARY KEY(ID)
);
CREATE TABLE OrderItems (
OrderID INT NOT NULL,
ItemID INT NOT NULL,
PRIMARY KEY(OrderID, ItemID),
FOREIGN KEY(OrderID) REFERENCES Orders(ID),
FOREIGN KEY(ItemID) REFERENCES Items(ID)
);
We have three tables in our extremely simplified Orders database. Obviously we are omitting a lot of information usually present in these tables, but we’re keeping things clean for demonstrative purposes.
- The
Orderstable, housing the date the Order was placed - The
Itemstable, which has a Name, Price, and Rating - The
OrderItemstable, keeping track of what Items are in each Order
Sample Data
Now let’s create some Items and Orders!
INSERT INTO Items (Name, Price, Rating) VALUES
('Foo', 10.99, 3),
('Bar', 50.01, 5),
('Fizz', 4.50, 5),
('Buzz', 1.99, 1);
-- Create Orders with auto-generated values
INSERT INTO Orders DEFAULT VALUES;
INSERT INTO Orders DEFAULT VALUES;
INSERT INTO Orders DEFAULT VALUES;
INSERT INTO OrderItems (OrderID, ItemID) VALUES
(1, 1), (1, 2), (1, 4), -- Foo, Bar, Buzz (Distinct ratings)
(2, 2), -- Bar (Single item)
(3, 1), (3, 2), (3, 3); -- For, Bar, Fizz (Rating tie)
Here we’ve created the Items Foo, Bar, Fizz, and Buzz. Both Bar and Fizz have a rating of 5, Foo has 3, and Buzz has 1. We’ve added three Orders (which in a fresh database, will create IDs 1, 2, and 3). Finally, we populated these created Orders with various items, annotated above.
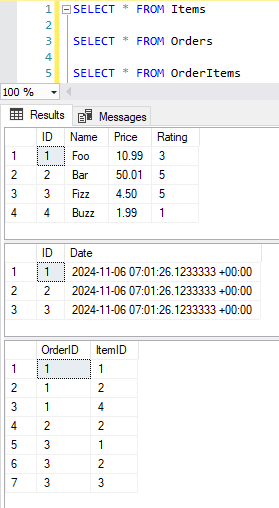
All tables are hydrated with sample Order data, with three Orders created.
Let’s Group Some Data!
Let’s get the highest-rated Item in each Order in our database. In a real system, this may be limited to a given user, date range, or other factors. For simplicity, we’ll use our entire dataset.
First Attempt: One By One
To get the highest-rated Item per Order, we must get groups of them, then pick the highest one. We obviously don’t want to pull every OrderItem record into memory, so we only select the highest item. To accomplish this in this first attempt we must run a query for each Order.
DECLARE @OrderID INT = 1; -- Repeat for each existing Order.
SELECT TOP 1 i.Name
FROM Items i
INNER JOIN OrderItems oi ON i.ID = oi.ItemID
WHERE oi.OrderID = @OrderID -- Query must be run for each Order, passing in 1, 2, and 3 separately
ORDER BY i.Rating DESC
This gets us what we want: The name of the highest-rated Item in the Order we specify.
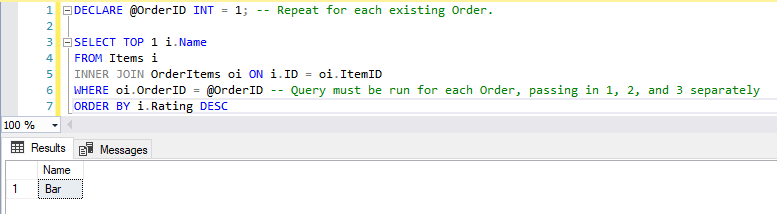
The highest-rated Item for Order 1 is the “Bar” Item.
Naturally this is inefficient, and we’d probably just say “pull all the data back and group/sort it in memory.”
No need! SQL gives us the tools to partition data within our queries.
Second Attempt: Partitioning
Instead of having to either pull all the data back and manually group/sort, or having to send N queries to the database, we can rely on the PARTITION BY operation in SQL. With this in conjunction with either the RANK() or ROW_NUMBER() functions, we can now effectively sort then filter by sub-groups within a single query.
SELECT * FROM
(
SELECT
oi.OrderID,
i.Name,
RANK() OVER (PARTITION BY oi.OrderID ORDER BY i.Rating DESC) 'Rank',
ROW_NUMBER() OVER (PARTITION BY oi.OrderID ORDER BY i.Rating DESC) 'Row'
FROM OrderItems oi
INNER JOIN Items i ON oi.ItemID = i.ID
) RankedItemsInOrders
WHERE Row = 1
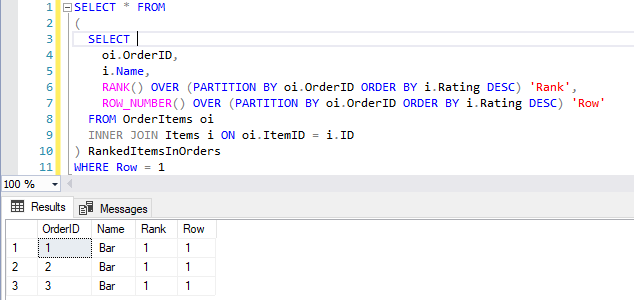
Using partitioning abilities within SQL, we can get all the highest-rated Items for all Orders at once.
The inner query builds out rankings for the Items per Order. The outer query’s WHERE clause then limits the results to just fetching the highest-ranked item, thus giving us the highest-rated item per Order. The secret sauce is within the PARTITION BY portion, where we dictate how the partition or ranking is done via the ORDER BY portion. In this case, we’re ranking by i.Rating DESC, and the ranks are divided by (one might say partitioned by) oi.OrderID.
To filter or otherwise use Rank or Row, you have to first create the projection, then select against that projection. This is why we have to wrap the partitioning query around SELECT * FROM and then add the WHERE after the fact.
You only need to use RANK() OR ROW_NUMBER() to accomplish this. If you use Rank you would replace WHERE Row = 1 with WHERE Rank = 1. Both are selected here so we can find out how these two functions differ.
RANK() vs. ROW_NUMBER()
If we remove WHERE Row = 1, we can see the full results of the inner query, which will also reveal the difference between the two functions. Let’s also select each Item’s Rating, because that’s what we’re ranking Items with.
SELECT * FROM
(
SELECT
oi.OrderID,
i.Name,
i.Rating,
RANK() OVER (PARTITION BY oi.OrderID ORDER BY i.Rating DESC) 'Rank',
ROW_NUMBER() OVER (PARTITION BY oi.OrderID ORDER BY i.Rating DESC) 'Row'
FROM OrderItems oi
INNER JOIN Items i ON oi.ItemID = i.ID
) RankedItemsInOrders
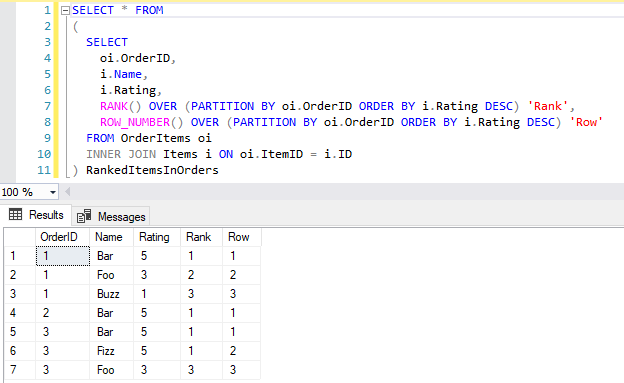
Removing the outer filter reveals the full list of ranked Items
For OrderID 1, things are simple: The Items are rated 5, 3, and 1, so both Rank and Row are 1, 2, and 3 respectively. OrderID 2 has a single Item in the whole Order, so there’s nothing notable here.
Take a look at OrderID 3’s Items, however. The Items Bar and Fizz both have a rating of 5. It’s a tie! Here’s where we see the difference between RANK() and ROW_NUMBER().
RANK()will give us the accurate ranking of each item based on the partitioned criteria. These two items are tied, therefore they both receive a ranking of 1.ROW_NUMBER()will give us a sequential ordering regardless of ties, and the tiebreaking it does is unstable, meaning you can potentially get differentROW_NUMBER()results for the same tied Items for each query run.
In our original query, this means WHERE Row = 1 will sometimes return Bar, sometimes return Fizz, for OrderID 3. This also means WHERE Rank = 1 will return both Bar and Fizz (which one comes first is still unstable).
So, Which is Better?
It Depends™! Do you only want a single “top item” and don’t care which one is returned? Do you want to get every top item, even if it means multiple per set? Depending on what your goals are, you can now satisfy either need, using either RANK() or ROW_NUMBER() in concert with PARTITION BY! The important thing is you are now keeping this operation where it belongs: Inside your database.